Today, Nomic released Nomic Embed, the first fully open source long context embedder that outperforms OpenAI Ada-002 and OpenAI text-embedding-3-small on both short and long context tasks. We also released a fully managed inference endpoint in our unstructured data platform Atlas, allowing anyone to build their own powerful RAG applications without having to worry about managing their own GPU infrastructure. In this post, we will show you how you can use this endpoint to build a RAG LLM using Nomic Atlas and MongoDB.
Nomic builds tools to enable anyone to interact with AI scale datasets and models. Nomic Atlas enables anyone to instantly visualize, structure, and derive insights from millions of unstructured datapoints. Our new text embedder is the backbone of Nomic Atlas, allowing users to search and explore their data in new ways.
MongoDB Atlas is a database service that drastically simplifies how people can build AI-enriched applications. It helps reduce complexity by allowing for low-latency deployments anywhere in the world, automated scaling of compute and storage resources, and a unified query API, integrating operational, analytical, and vector search data services.
Retrieval augmented generation, as introduced in Lewis et al. (2023), equips a traditional generative language model with a retrieval database. This allows the model to quickly incorporate domain specific and up-to-date information into its answers without having to retrain the model. This can significantly improve the quality of model responses and dramatically reduce hallucinations when compared to a traditional language model. In this post, we are going to show you how you can build your own RAG LLM system using Nomic and MongoDB.
This tutorial will require you to have accounts on both Nomic Atlas and MongoDB. You can sign up for a Nomic Atlas account here.
You also need to setup a MongoDB Atlas account. You can do this by visiting the MongoDB Atlas website.
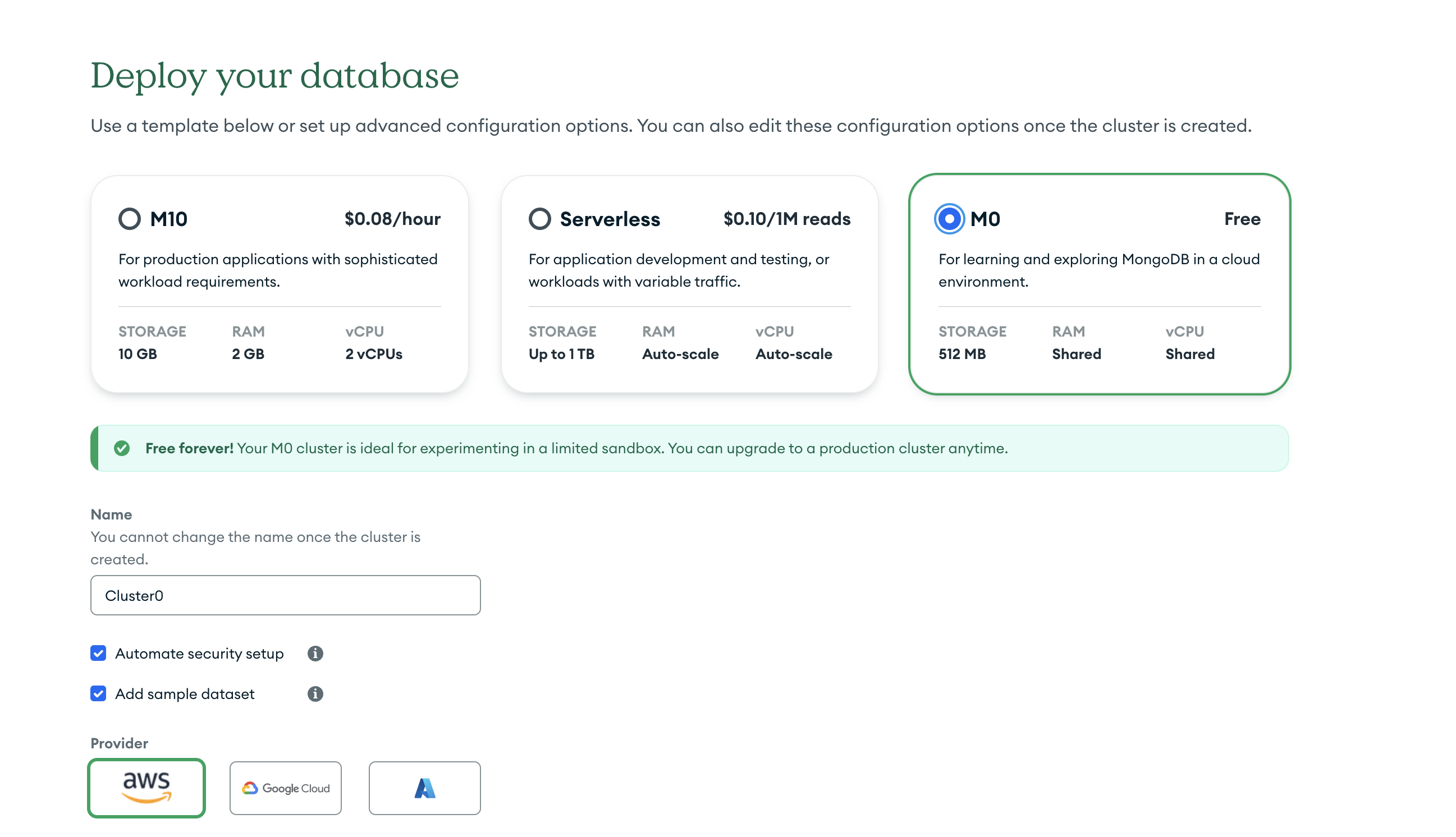
Once your account is created, you need to create a database and should be prompoted to do so.
Click on M0 to create a free database
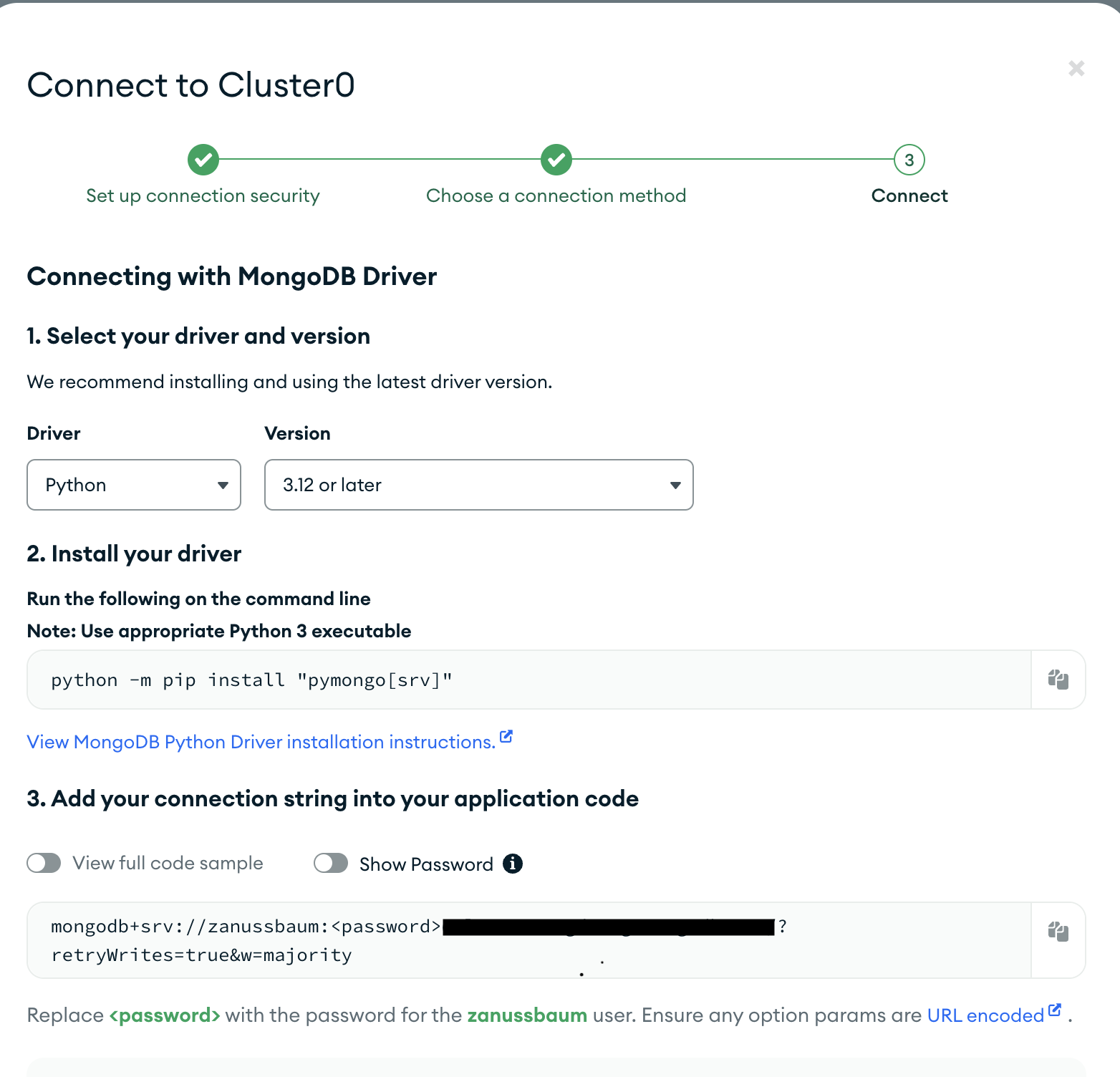
After doing so, MongoDB will prompt you on how you want to connect to your database. Make sure to save your connection string as you will need it later!
Create a Python environment. For this example, we will use virtualenv:
python3 -m venv env
source env/bin/activate
pip install nomic "pymongo[srv]" requests tqdm
Now, we can import the libraries we need to run our script. Get your Nomic API key from the Nomic Atlas website by running
nomic login
where you will be prompted to retrieve an API key. Next you will login to Nomic Atlas and create a MongoDB client. Your MongoDB client should look
import nomic
import pymongo
NOMIC_API_KEY = "<NOMIC_API_KEY>"
nomic.cli.login(NOMIC_API_KEY)
MONGO_URI = (
"mongodb+srv://zach:<password>@<clusterid>?retryWrites=true&w=majority"
)
client = pymongo.MongoClient(MONGO_URI)
Now, we need a function that will generate our embeddings. We will use the Nomic Embedding API to do this.
def generate_embeddings(input_texts: List[str], model_api_string: str, task_type="search_document") -> List[List[float]]:
"""Generate embeddings from Nomic Embedding API.
Args:
input_texts: a list of string input texts.
model_api_string: str. An API string for a specific embedding model of your choice.
task_type: str. the task type for the embedding model. Defaults to "search_document". One of `search_query`, `search_document`, `classification`, or `clustering`.
Returns:
a list of embeddings. Each element corresponds to the each input text.
"""
start = time.time()
outputs = embed.text(
texts=[text for text in input_texts],
model=model_api_string,
task_type=task_type,
)
print(f"Embedding generation took {str(time.time() - start)} seconds.")
return outputs["embeddings"]
embedding_model_string = 'nomic-embed-text-v1' # only one model is available at the moment.
vector_database_field_name = 'nomic-embed-text' # define your embedding field name.
NUM_DOC_LIMIT = 250 # the number of documents you will process and generate embeddings.
sample_output = generate_embeddings(["This is a test."], embedding_model_string)
print(f"Embedding size is: {str(len(sample_output[0]))}")
The embedding size should print 768 if you are using the default model.
Additionally, Nomic Embed uses prefixes to improve the quality of the embeddings.
For RAG applications, we recommend using the search_document task type for the texts you will store in the vector index and search_query for
all texts you want to retrieve against.
Now, we need to generate embeddings for the documents in our MongoDB database. We will be using the sample Airbnb dataset for this example.
To see what's in the database, you can navigate to the dataset by clicking on "Browse Collections"
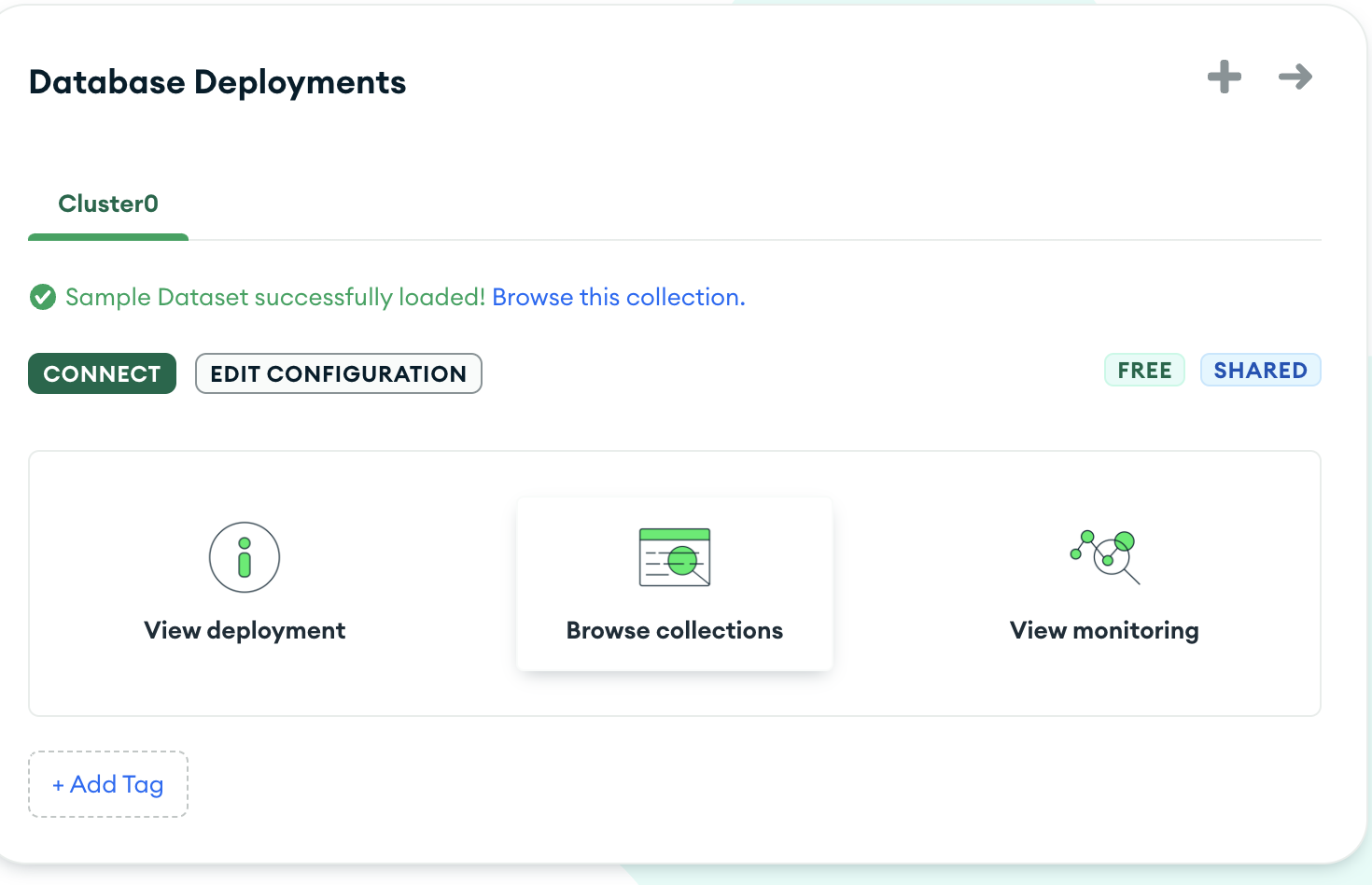
and then you should see the sample_airbnb database
We wil luse the listingsAndReviews collection for this example.
For each document, we will extract the fields we want to generate embeddings for and then generate embeddings for each document. Each document will then be uploaded to MongoDB.
db = client.sample_airbnb
collection_airbnb = db.listingsAndReviews
keys_to_extract = [
"name",
"summary",
"space",
"description",
"neighborhood_overview",
"notes",
"transit",
"access",
"interaction",
"house_rules",
"property_type",
"room_type",
"bed_type",
"minimum_nights",
"maximum_nights",
"accommodates",
"bedrooms",
"beds",
]
for doc in tqdm(
collection_airbnb.find({"summary": {"$exists": True}}).limit(NUM_DOC_LIMIT),
desc="Document Processing",
total=NUM_DOC_LIMIT,
):
extracted_str = "\n".join([k + ": " + str(doc[k]) for k in keys_to_extract if k in doc])
if vector_database_field_name not in doc:
doc[vector_database_field_name] = generate_embeddings([extracted_str], embedding_model_string)[0]
collection_airbnb.replace_one({'_id': doc['_id']}, doc)
In the MongoDB Atlas Dashboard, the embedding will look something like this:
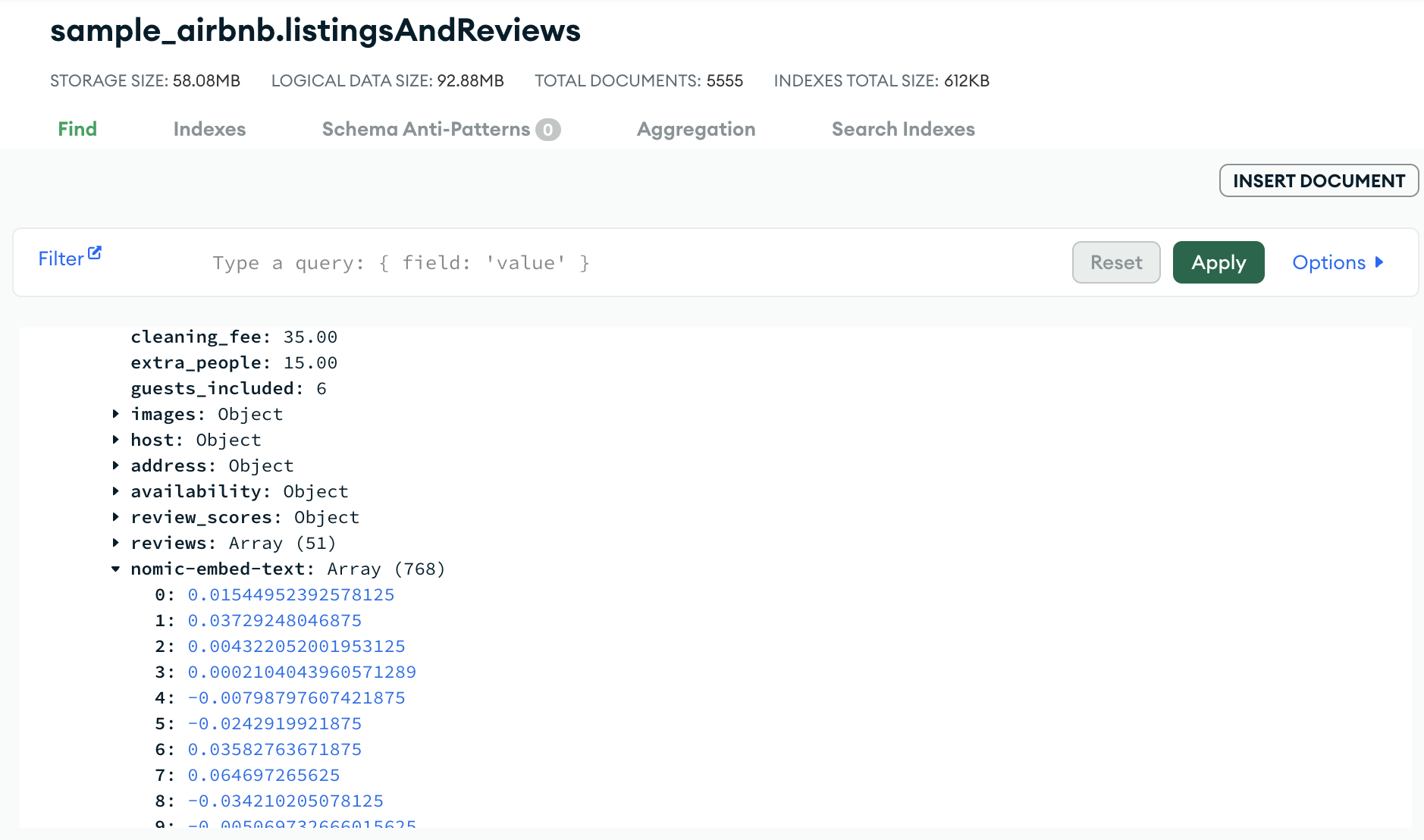
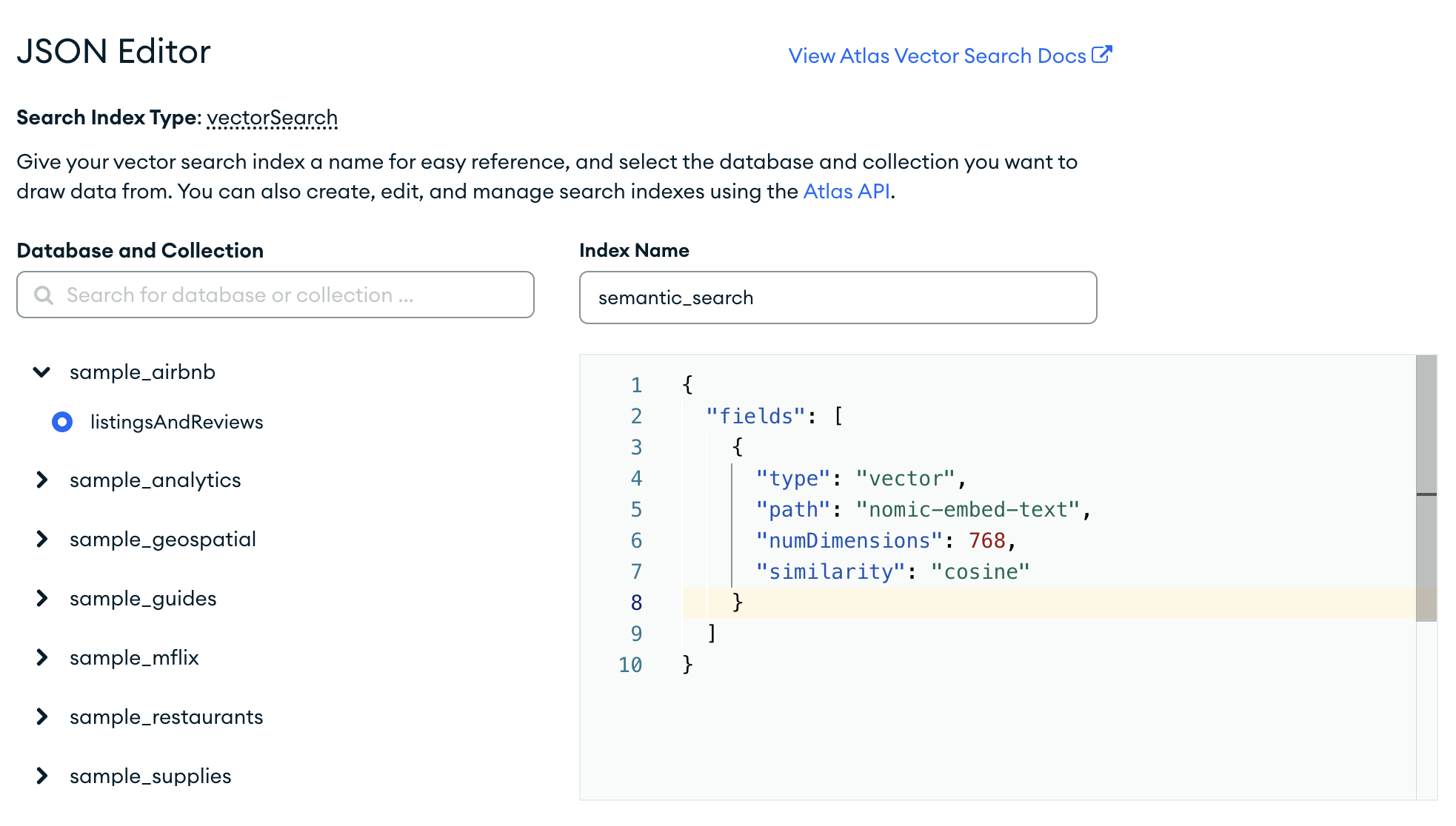
Before we retrieve our documents, we need to create a search index on our embedding field.
To do so, navigate to "Atlas Search",
and then click on "Create Search Index". Then, click on "JSON Editor".
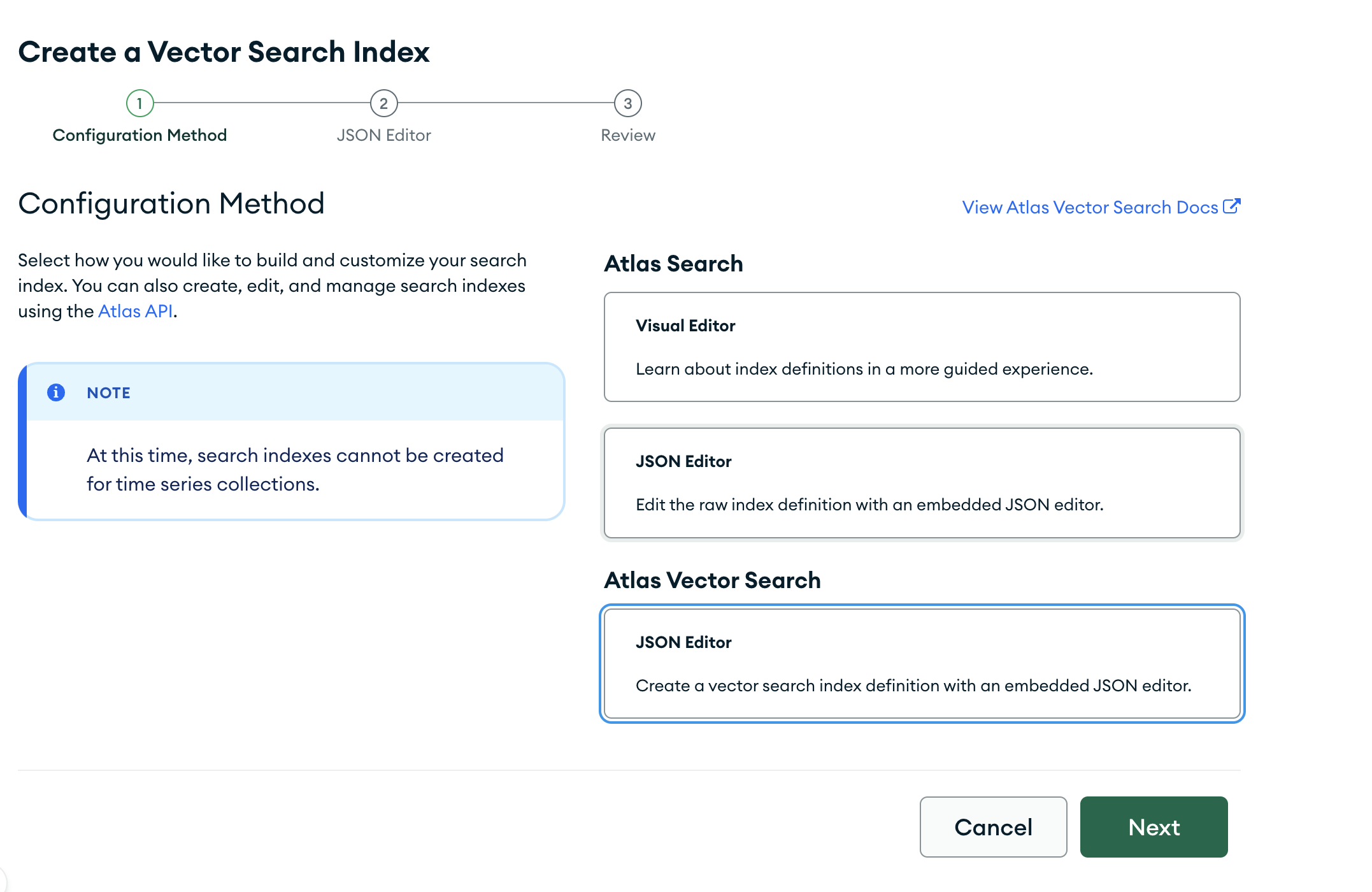
Paste the following JSON into the editor, click next, then and click "Create Index".
{
"fields": [
{
"type": "vector",
"path": "nomic-embed-text",
"numDimensions": 768,
"similarity": "cosine"
}
]
}
It should look like this:
Now onto the fun part! We will now retrieve documents from our MongoDB database using our search index.
query = "What's an apartment with a great view near the water for 4 or more people? I would love to be near restaurants and bars."
query_emb = generate_embeddings([query], embedding_model_string, task_type="search_query")[0]
results = collection_airbnb.aggregate(
[
{
"$vectorSearch": {
"queryVector": query_emb,
"path": vector_database_field_name,
"numCandidates": 100, # this should be 10-20x the limit
"limit": 10, # the number of documents to return in the results
"index": "semantic_search", # the index name you used in Step 4.
}
}
]
)
results_as_dict = {doc['name']: doc for doc in results}
print(f"From your query \"{query}\", the following apartments were found:\n")
print("\n".join([str(i + 1) + ". " + name for (i, name) in enumerate(results_as_dict.keys())]))
This will get the top 10 documents that are most similar to our query given 100 candidates.
Now, we can generate text from our retrieved documents using a LLM. We will use an open source model from HuggingFace.
Note! You can use any model you want here, but we are using an open source model for transparency and auditability.
If you choose to use an open source model you will need to follow the next section to setup the inference endpoint. Depending on the model you use, you may also need a GPU to run the model.
We will use Nous-Hermes-2-Mixtral-8x7B-DPO for this example.
To run our model, we will be using Text-Generation-Inference-Server.
Now, to serve the model, run the following command:
docker run --gpus all --shm-size 1g -p 8080:80 -v $volume:/data ghcr.io/huggingface/text-generation-inference:1.3 --model-id $model --num-shard <num_gpus> --max-total-tokens=32768 --max-input-length=4096
This will setup the necessary inference endpoint to run the model and should be hosted at http://127.0.0.1:8080.
Now, we can generate text from our retrieved documents using the inference endpoint. Note, we need to add special instructions to our prompt, as defined in the model documentation. This may not be the case for all models so if you are not using the same model, please update the prompt accordingly.
def generate_text(prompt):
# URL for the POST request
url = 'http://127.0.0.1:8080/generate'
# Data payload as a Python dictionary, which will be converted to JSON
data = {
"inputs": prompt,
"parameters": {
"max_new_tokens": 750,
"temperature": 0.8,
"repetition_penalty": 1.1,
"do_sample": True,
},
}
headers = {'Content-Type': 'application/json'}
# Make the POST request and capture the response
response = requests.post(url, data=json.dumps(data), headers=headers)
return response.json()['generated_text']
task_prompt = (
"From the given airbnb listing data, choose an apartment with a great view near a coast or beach for 4 people to stay for 4 nights. "
"I want the apartment to have easy access to good restaurants. "
"Tell me the name of the listing and why this works for me."
)
keys_to_add = (["summary", "notes", "description", "neighborhood_overview"],)
listing_data = ""
for doc in results_as_dict.values():
listing_data += f"Listing name: {doc['name']}\n"
for k, v in doc.items():
if not (k in keys_to_add) or ("embedding" in k):
continue
if k == "name":
continue
listing_data += k + ": " + str(v) + "\n"
listing_data += "\n"
augmented_prompt = (
"<|im_start|>system"
"You are a sentient, superintelligent artificial general intelligence, here to teach and assist me.<|im_end|>"
"<|im_start|>user\n"
f"{task_prompt}"
"airbnb listing data:\n"
f"{listing_data}\n\n"
)
print(generate_text(augmented_prompt))
The output looks like this:
Among these options, "Amazing and Big Apt, Ipanema Beach" is likely the best choice because it offers both a stunning ocean view from its location on Ipanema Beach, which is highly desirable for relaxing coastal vacations, as well as easy access to top-rated international cuisine that Brazil's vibrant Rio de Janeiro city has to offer. Notably, all apartments mentioned provide accommodation for four guests, so any can be suitable based on your party size requirement. However, what sets this specific apartment apart is its exceptional location paired with spacious accommodations that other listings may not offer. Plus, being close to many excellent dining options will further enhance your overall experience during your four-night stay.
Remember, you could always revisit my suggestions if none of them seem perfect yet. There might be more Airbnb properties matching your criteria better than the ones listed above. If needed, we can refine the search parameters further and continue our quest for finding an ideal vacation rental for you!
To verify that the selected listing is indeed a good choice, we can look at the summary of the listing:
for k, v in results_as_dict["Amazing and Big Apt, Ipanema Beach."].items():
if k in keys_to_extract:
print(f"{k}: {v}")
name: Amazing and Big Apt, Ipanema Beach.
summary: Fantastic apt for 6 people a block from the beach of Ipanema. Fun, comfort and do everything on foot: bars, restaurants or stroll through the neighborhoods Leblon and Copacabana. In the Carnival, "Banda de Ipanema", show up in front of the building.
space: In the heart of Ipanema, the apartment is very clean, comfort, big espace and amazing view. Perfect for the family or friends.
description: Fantastic apt for 6 people a block from the beach of Ipanema. Fun, comfort and do everything on foot: bars, restaurants or stroll through the neighborhoods Leblon and Copacabana. In the Carnival, "Banda de Ipanema", show up in front of the building. In the heart of Ipanema, the apartment is very clean, comfort, big espace and amazing view. Perfect for the family or friends. Close to the subw Bus station in front of the building You can do everything in Ipanema on foot.
neighborhood_overview:
notes:
transit: Close to the subw Bus station in front of the building You can do everything in Ipanema on foot.
access:
interaction:
house_rules:
property_type: Apartment
room_type: Entire home/apt
bed_type: Real Bed
minimum_nights: 1
maximum_nights: 1125
accommodates: 6
bedrooms: 3
beds: 4
It fulfills all of our requirements!
This blog post showed you how you can implement a RAG LLM using Nomic and MongoDB. We have shown how you can use Nomic to generate embeddings for your Data Sources, add them to a MongoDB Vector Store, and use an open source LLM to generate text from your retrieved documents. By choosing an open source embedding model, you get full transparency auditability over every aspect of your technology stack. Further, by having access to the code and data behind this model, you can easily tweak it and make a domain specific model for even better performance.